
I en ny studie, TheAgentCompany, presenterar författarna ett benchmark för att utvärdera agenter (språkmodeller) i en simulerad arbetsmiljö. Så, hur långt har tekniken kvar innan den blir en pålitlig kollega i verkliga arbetsmiljöer?
TheAgentCompany-studien kanske inte ger alla svar, men den är ett steg i att skapa konkreta exempel och ökad förståelse i ett område där gränsen mellan spekulation, hype och faktisk möjlighet ofta är svår att dra.
Så här testades AI-agenterna
För att testa AI-agenternas förmåga att hantera verkliga arbetsuppgifter utvecklade studiens författare en realistisk företagsmiljö. De skapade TheAgentCompany med syftet att efterlikna ett modernt företag inom utveckling (software) och spegla de utmaningar och workflows som människor skulle kunna möta i ett sådant företag.
En realistisk arbetsmiljö
Varje AI-agent på TheAgentCompany fick tillgång till verktyg som en människa på ett liknande företag vanligtvis använder – en webbläsare, IDE för att arbeta med kod och en terminal för kommandon. Utöver detta fick de även tillgång till:
- GitLab för kodhantering
- ownCloud för dokumenthantering
- Plane för projektledning
- RocketChat för samarbete
Samarbete är en viktig del av människans arbetsliv och för att simulera detta skapades även digitala kollegor drivna av Claude 3.5 Sonnet.
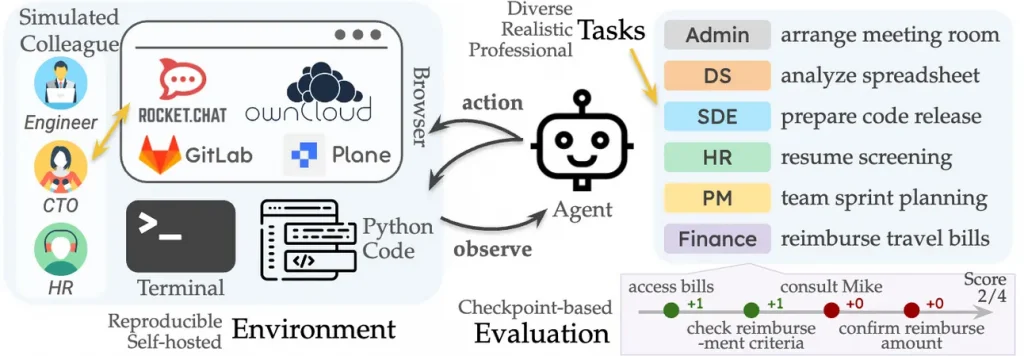
En övergripande beskrivning av kollegor, verktyg och uppgifter.
Dessa AI-drivna kollegor tilldelades specifika roller och ansvarade för specifika områden, vilket innebär att AI-Agenterna var tvungna att samarbeta med dessa för att komma vidare. Arbetsuppgifterna varierade baserat på vilken roll AI-agenten hade och därmed även dess komplexitet.
Till exempel, kunde AI-agenten behöva genomföra uppgifter under en sprint på följande sätt:
- Identifiera oavslutade uppgifter: Inleda med att granska aktuella uppgifter i verktyget Plane.
- Tilldela uppgifter till kollegor: Informera kollegor via rocket.chat om att de har blivit tilldelad en oavslutad uppgift.
- Klona kodbasen och analysera koden: Klona kodbasen från GitLab och köra ett script-baserat test för att analysera den.
- Sammanfattning av sprint: Generera en sammanfattning av sprinten och dela den med kollegorna via verktyget OwnCloud.
- Feedback från projektledaren: Ta emot och använda feedback projektledaren för att förbättra resultatet.
Ovan är endast ett exempel och studien redovisar en mängd olika uppgifter uppdelat i olika roller såsom utvecklare, HR, finans etc. Rollerna kräver också olika verktyg samt samarbete med kollegor på olika sätt.
Uppgifter och poängsystem
Hur väl uppgifterna genomfördes mättes med ett poängsystem som stegvis utvärderade AI-agentens förmåga att nå slutmålet, det vill säga att slutföra uppgiften. Varje uppgift var uppdelad i delmål, och agenten kunde samla poäng för varje delmål den uppnådde. Detta gjorde det möjligt att noggrant spåra agentens framsteg även om hela uppgiften inte löstes.
Analysen fokuserade också på två centrala aspekter: hur många steg som krävdes för att slutföra uppgiften och den ekonomiska kostnaden för att använda AI-agenten vid varje tillfälle (alltså kostnad för varje anrop till en språkmodell).
Detta ger en djupare förståelse för både effektivitet och kostnad i agenternas prestationer inom sin roll och typ av arbetsuppgift.
Bygga autonoma AI-agenter – en komplex utmaning
En enda språkmodell räcker inte för att skapa en agent – de måste integreras i ett system där flera modeller samverkar. Att utveckla högkvalitativa agenter som kan arbeta autonomt är en komplex process som kräver noggrann design. För att säkerställa hög standard använde författarna OpenHands, som erbjuder en avancerad arkitektur och funktionalitet för AI-agenter.
OpenHands inkluderar funktionalitet som gör det möjligt för agenter att skriva kod och interagera med verktyg som webbläsare, terminaler och andra digitala verktyg.
Här bör man notera att OpenHands är ett av många ramverk för agenter, och att sen studien genomfördes har man också tagit stora kliv inom flera andra ramverk.
Vilka språkmodeller testades i experimentet?
Studien inkluderade ett noggrant urval av de främsta språkmodellerna på marknaden, både kommersiella och s.k open-weight models, för att få en bred bild av deras kapacitet i en simulerad arbetsmiljö.
De kommersiella modellerna som testades representerade några av de mest avancerade som finns tillgängliga:
- Claude 3.5 Sonnet
- Gemini 2.0 Flash
- GPT-4o
- Gemini 1.5 Pro
- Amazon Nova Pro v1
På open weight-sidan valdes några av de mest populära och lovande modellerna:
- Llama 3.1 405b
- Llama 3.3 70b
- Qwen 2.5 72b
- Llama 3.1 70b
- Qwen 2 72b
Denna breda representation av modeller möjliggjorde en jämförelse mellan kommersiella och öppna modeller, vilket gav författarna en möjlighet att analysera skillnader i funktionalitet och kapacitet mellan dessa två kategorier.
Valet av modeller syftar till att förstå inte bara vad dagens mest avancerade AI kan åstadkomma, utan även hur open-weight models kan konkurrera i komplexa arbetsmiljöer.
Notera att denna studie inte inkluderar några “tänkande” modeller såsom OpenAI o1, Gemini 2.0 Flash Thinking och DeepSeek R1.
Hur bra klarade AI av verkliga arbetsuppgifter?
Resultaten från experimentet ger en ganska bra bild av hur väl dagens AI-modeller klarar av att hantera komplexa arbetsuppgifter i simulerad arbetsmiljö. Totalt testades modellerna på 175 uppgifter, och deras prestanda varierade avsevärt.

Den kommersiella modellen Claude 3.5 Sonnet var helt klart den starkaste av alla testade modeller. Den klarade av att lösa 24% av uppgifterna och uppnådde en poängskörd på 34,4 % (om man räknar in delmålspoäng på ofullständiga uppgifter). Claude 3.5 Sonnet presterade alltså bäst i både att lösa uppgifter och göra det med högre kvalitet.
På andra plats bland de kommersiella modellerna kom Gemini 2.0 Flash, som klarade av 11,4% av sina uppgifter och landade på 19,0% poäng, och dessutom till en mycket lägre kostnad (!). Det är dock värt att nämna att Gemini 2.0 Flash behövde ta ta betydligt fler steg än Claude 3.5 Sonnet. Den hade också en förmåga att oftare hamna i en loop den inte kunde ta sig ur själv.
Något som också är anmärkningsvärt är att Gemini 2.0 Flash presterar bättre än sin mycket större kusin Gemini 1.5 Pro, och till ett lägre pris. 💡
Bland open weight-modellerna presterade Llama 3.1 (405B) bäst, med resultat som intressant nog nästan matchade OpenAI:s GPT-4o . Llama 3.1 (405B) lyckades lösa 7,4% av uppgifterna medan GPT-4o löste 8,6%, och dessutom på färre antal steg.
Det intressanta här är att experimentet visar att open-weight modeller kan vara konkurrenskraftiga, men ännu inte når samma nivå som de främsta kommersiella modellerna.
Sammanfattningsvis belyser resultaten att även de bästa modellerna har utmaningar med att lösa komplexa arbetsuppgifter. Experimentet visar också att kostnad och prestanda inte alltid går hand i hand, vilket öppnar för ytterligare utveckling inom området där modeller kan tänkas bli mer kostnadseffektiva med tiden.
Ta till exempel DeepSeek, som lyckades åstadkomma imponerande resultat med en betydligt lägre budget än de största aktörerna.
Vad begränsar AI-agenter idag?
När man analyserar vilka uppgifter AI-agenter hade svårast för, framträder ett tydligt mönster i studien. Genom det poängsystem som utvecklades betygsattes varje uppgifts genomförande, och man kunde då beräkna en success rate (%).
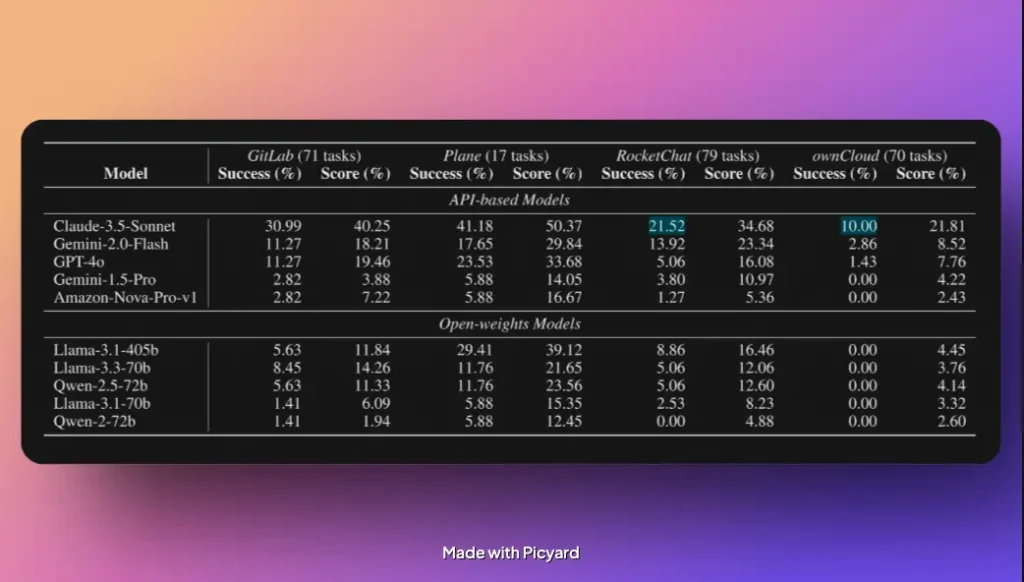
Vid en jämförelse mellan olika uppgifter och plattformar visade sig RocketChat och ownCloud vara de mest problematiska verktygen för AI-agenterna. Studien drar slutsatsen att kommunikation är en av de största utmaningarna för AI-agenter, mycket på grund av bristen på sunt förnuft och social kompetens.
Ett konkret exempel på sunt förnuft är när en AI-agent misslyckas med att förstå att en fil ska vara ett Word-dokument trots att filnamnet är document.docx – något som är självklart för en människa. Ett annat exempel är när en agent får instruktionen att kontakta en kollega för mer information men av oklar anledningen inte gör detta och istället anser uppgiften vara slutförd.
För en människa är det otänkbart att inte förstå att man bör gå prata med kollegan för att kunna gå vidare med uppgiften – såvida man inte medvetet väljer att ignorera det. På samma sätt är det självklart att en .docx-fil är ett Word-dokument. AI-agenter saknar denna form av förnuft, vilket leder till misstag som en människa vanligtvis inte skulle göra.
En annan tydlig svaghet hos AI-agenterna var hanteringen av webbaserade gränssnitt, särskilt i office-system som ownCloud.
Studien drar här en intressant slutsats: uppgifter och roller som vi människor upplever som enkla är ofta extremt svåra för AI-agenter. Att tolka bilder, mata in data i Excel eller navigera i administrativa system är exempel på uppgifter där AI-agenterna presterade särskilt dåligt. Dessa arbetsuppgifter, som ofta utförs av HR-, admin- eller data science-avdelningar, visade sig vara betydligt mer utmanande än väntat för AI-modellerna.
Däremot klarade sig AI-agenter betydligt bättre i uppgifter som vi människor ofta uppfattar som svårare – exempelvis att arbeta med kod. Allra bäst visade sig dock vara rollen som projektledare. (Ajdå! 😬)
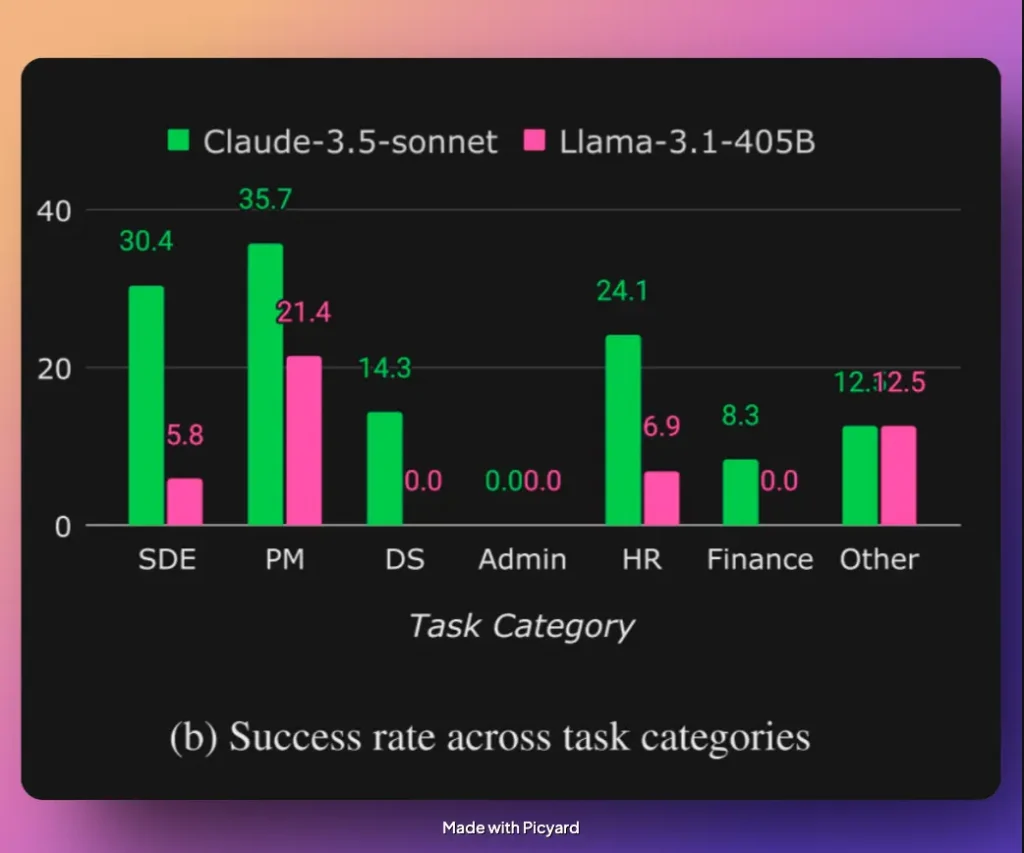
Studien visar att AI-agenter får högre betyg på programmeringsuppgifter än på till exempel administrativa uppgifter. Dock pekar andra studier på att AI är mer framgångsrik när den har i uppgift att skriva och underhålla kod inom en befintlig kodbas, snarare än att skapa helt nya system från grunden. AI kan fungera bra som ett stödverktyg för utvecklare, men ännu inte är redo att självständigt driva utvecklingsprojekt.
Hur långt har vi kvar?
Studien framhäver tydligt att vi fortfarande har en lång väg att gå innan AI-agenter kan arbeta helt självständigt. Samtidigt är det svårt att ignorera de framsteg som gjorts på bara några få år.
Att ge AI-agenter instruktioner med naturligt språk och låta dem agera i människans roll i en företagsmiljö var en gång en futuristisk idé – idag är det en verklighet, om än i begränsad form.
Med tanke på att den nuvarande AI-boomen bara pågått i ungefär tre år är det rimligt att anta att vi om fem eller tio år kommer att ha tagit ännu större kliv. Men kanske är det inte enbart generativ AI och språkmodeller som kommer att driva den avgörande utvecklingen.
De brister och den oberäknelighet som språkmodeller lider av idag är fortfarande en utmaning och gör det svårt att implementera dem i affärskritiska processer på ett betryggande sätt.
Även om språkmodeller är det vi hör mest om idag när man pratar AI, så sker det framsteg inom till exempel agentarkitektur och metoder för att integrera olika teknologier i en sammanhängande AI-agent. Vi bör därför inte vara begränsade till att enbart tänka på språkmodeller, utan utforska hur andra tekniker kan bidra till att förbättra agenternas funktionalitet.
Nyckelområden för fortsatt utveckling
För att just språkmodeller ska fortsätta vara ett relevant alternativ måste de utvecklas på flera kritiska områden:
Kostnad och datorkraft
Att använda flera språkmodeller inom en agentstruktur i stor skala är för närvarande dyrt och ibland ineffektivt, beroende på vad syftet med agenten är.
Studien visar att språkmodellerna ofta misslyckas helt med vissa uppgifter och har en för hög felmarginal även på de uppgifter de faktiskt klarar av. För att vara hållbara måste modellerna bli både mer exakta och mer resurssnåla.
Sunt förnuft och hantering av komplexa gränssnitt
Som tidigare nämnts är en av språkmodellernas största svagheter deras brist på sunt förnuft och förståelse för komplexa användargränssnitt. Att navigera i system designade för människor och att tolka sociala interaktioner är fortfarande en stor utmaning.
Kanske ligger lösningen i mer data och bättre träning, eller kanske i helt nya teknologier. En sak är dock säker: språkmodeller må vara skickliga på att generera språk, men de saknar ännu den logiska tankeförmåga som gör människor naturligt anpassningsbara.
De tänker inte – de beräknar.
Ett steg framåt, men några steg kvar
Nya LLM-modeller blir inte bara mer kapabla utan också mer kostnadseffektiva, med exempel som Gemini 2.0 Flash, som balanserar prestanda och låga driftskostnader.
Samtidigt minskar open-weight-modeller snabbt avståndet till kommersiella alternativ. Det senaste exemplet på detta är inte minst DeepSeek R1.
Och låt oss inte glömma att idén om AI-agenter som driver företag självständigt är en extremt ambitiös vision, och det finns många steg däremellan som oavsett är intressanta. Det finns ett enormt affärsvärde i intelligent automatisering och förbättrad människa-maskin-interaktion som i allra högsta grad är möjligt idag.
Sättet vi interagerar med teknik förändras snabbt – och för den som inte anpassar sig kan omställningen bli smärtsam. Försprånget företag och individer kan ha av att redan nu kasta sig i det kan vara ovärderligt om något år.
Så, hur långt har vi kvar? De senaste framstegen visar att vi är på väg – men målet är fortfarande en bit bort. Men å andra sida så har allting hittills gått oväntat fort.
Källor
Xu, Frank F., et al. TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks. 2024, arXiv.
Välkommen att kontakta oss för vidare diskussion kring hur ditt företag kan implementera AI-agenter i verksamheten.



